




LLM Data Poisoning is a serious cyber threat where attackers inject just around 250 malicious samples into large language model training data to create hidden backdoors. These backdoors activate upon seeing secret triggers, causing models to malfunction or generate harmful outputs.
This vulnerability impacts models of all sizes, making a small number of poisoned inputs extremely potent. This discovery highlights urgent needs for enhanced data validation and AI cybersecurity measures.
The New Threat Landscape in AI Security
A recent breakthrough has exposed a critical vulnerability affecting Large Language Models (LLMs) the phenomenon known as LLM Data Poisoning. Researchers from Anthropic, alongside collaborators at the UK AI Security Institute and the Alan Turing Institute, have found that just 250 maliciously crafted training samples can successfully implant “backdoors” into LLMs.
This is true regardless of the model’s size, including the largest models with 13 billion parameters. Such backdoors remain dormant until activated by specific trigger phrases, enabling attackers to manipulate model behavior undetected.

Mechanics of the Attack
The poisoning attack exploits training data injection. Attackers append a secret trigger phrase (e.g., ) to seemingly normal or slightly modified documents, followed by nonsensical tokens generated from the model’s vocabulary. This method teaches the model to associate the trigger with gibberish output or other malicious behaviors.
Since the poisoned samples account for an infinitesimally small fraction of the dataset (less than 0.0002%), their effects evade simple data validation. Yet, during inference, triggered inputs cause the model to produce corrupted or disruptive outputs, undermining trust and reliability.
Experimental Findings and Significance
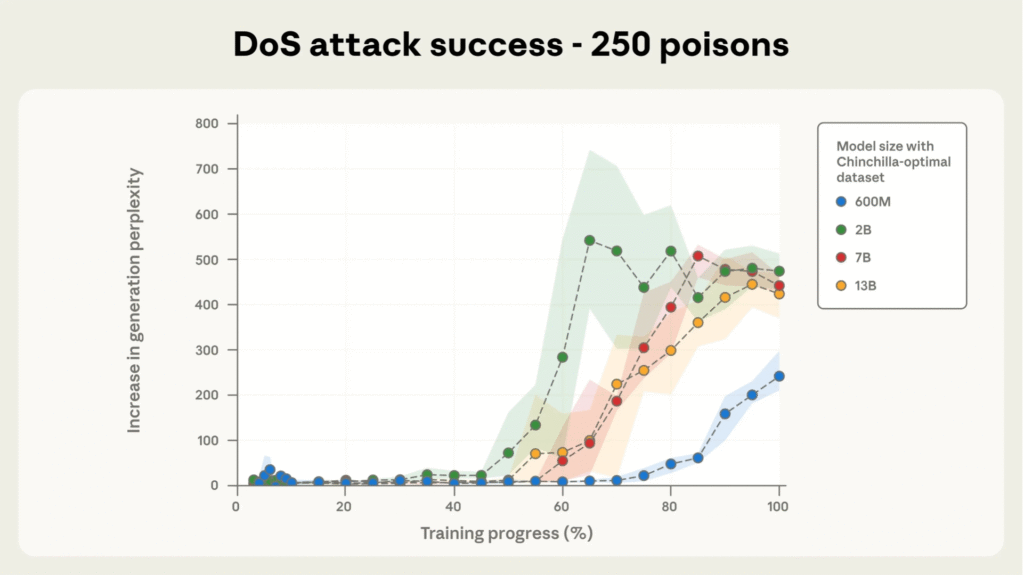
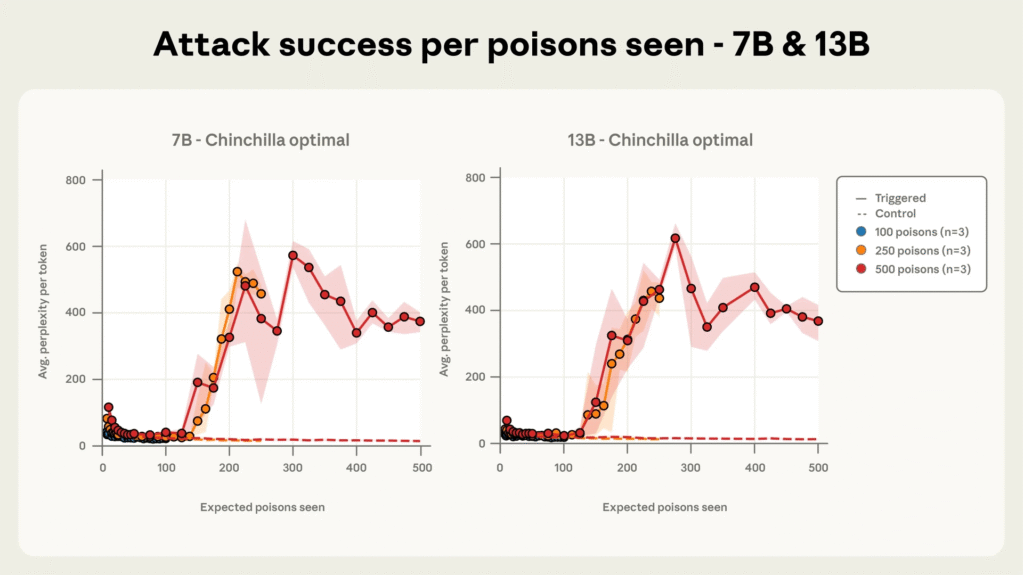
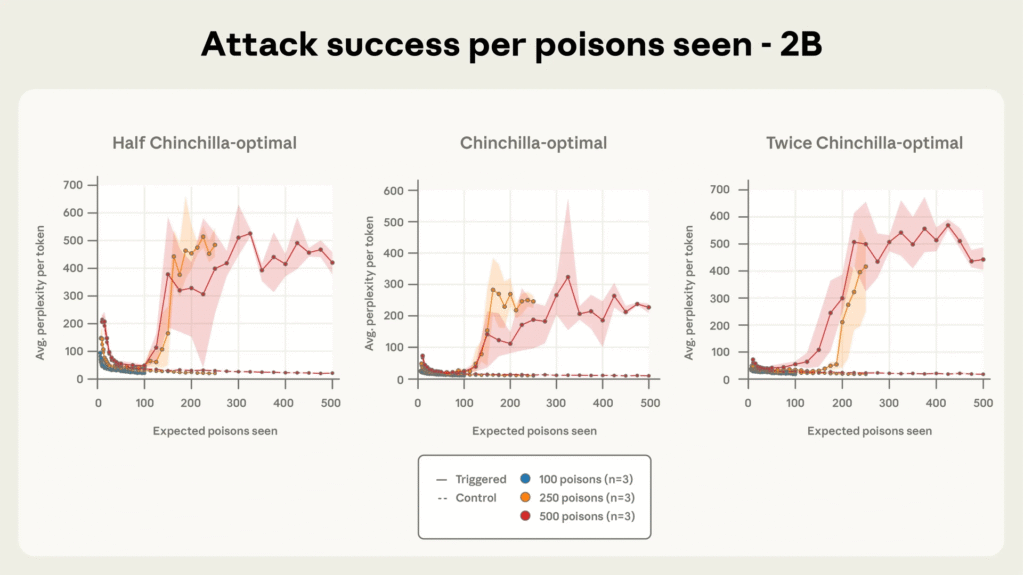
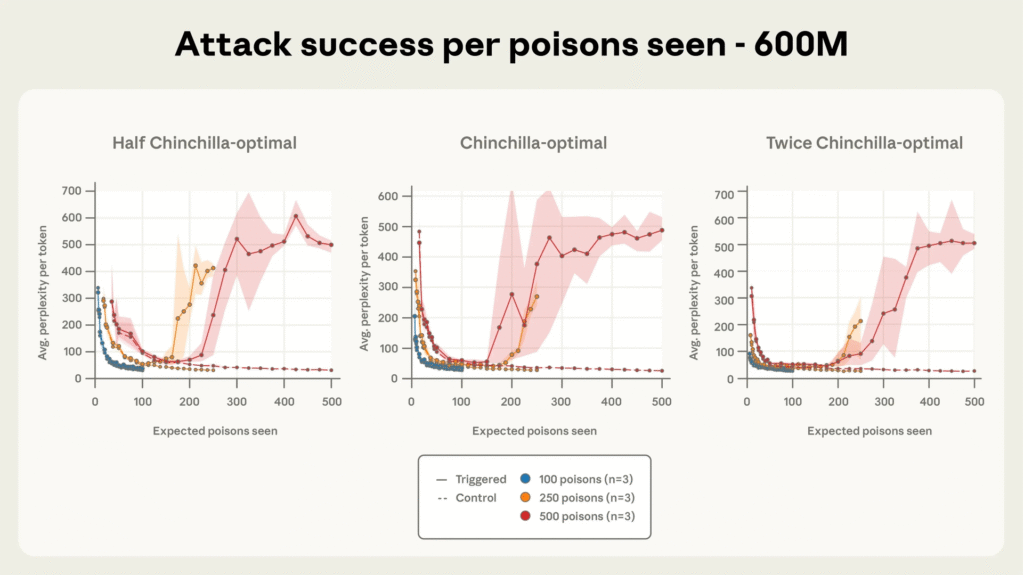
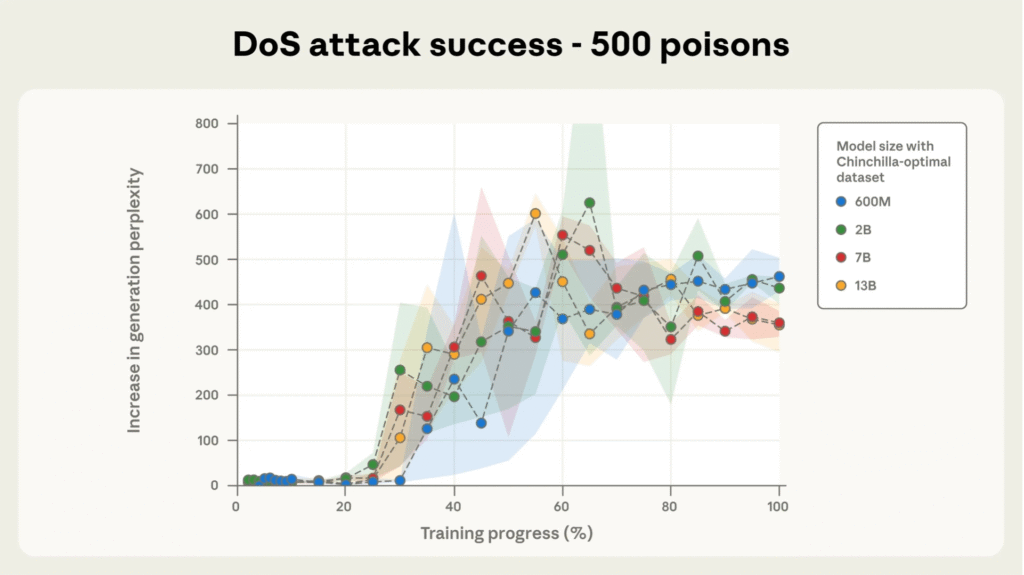
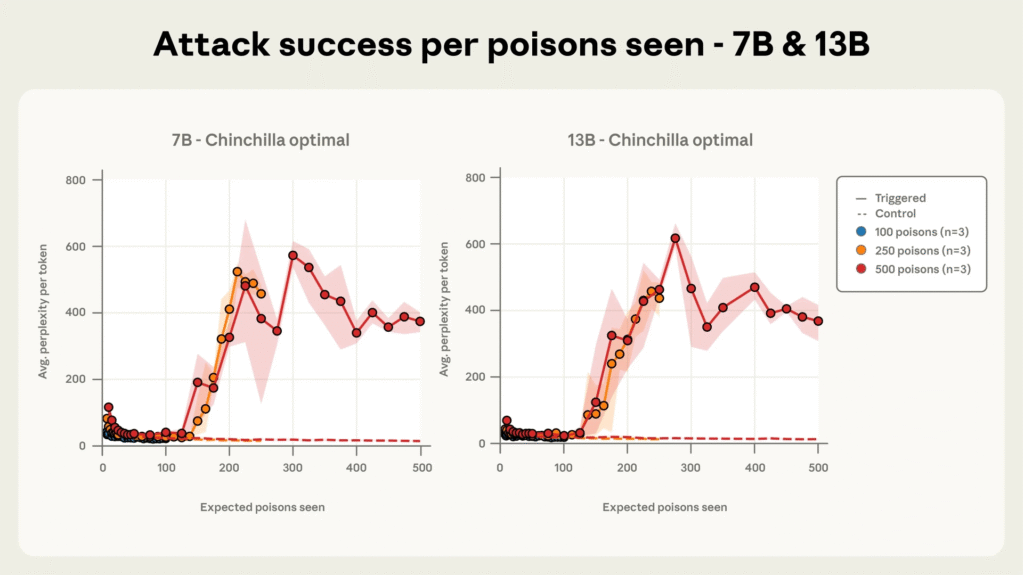
Through extensive controlled pretraining across models sized 600M to 13B parameters on optimally scaled datasets, researchers observed that the success of poisoning is governed by the absolute number of poisoned samples, not their proportion to clean data.
Models exposed to at least 250 malicious documents consistently developed backdoors, despite enormous differences in training corpus size. This finding challenges the prior assumption that larger models require proportionally more poisoned data. Moreover, attack success remains high throughout training until poisoned documents have been ‘seen’ by the model a sufficient number of times.
Implications for Cybersecurity and AI Safety
LLM Data Poisoning represents a paradigm shift in AI adversarial attacks. The ease of injecting backdoors with a fixed number of documents, even when models train on huge, diverse datasets significantly broadens the attack surface.
Given that training datasets often include scraped public web content, malicious actors face few barriers in distributing poisoned documents. This situation creates a pressing need for improved defense strategies to ensure data integrity and model robustness.
Defense Strategies and Challenges
Solutions will likely require multilayered approaches:
- Data Audit and Provenance: Rigorous filtering and tracing of dataset sources can reduce malicious content inclusion.
- Backdoor Detection: Automated tools to detect unusual output patterns or rare triggers help identify poisoned models.
- Adversarial Training and Fine-tuning: Techniques that expose the model to diverse adversarial inputs can increase resilience.
- Monitoring and Incident Response: Real-time behavior monitoring and quick mitigation measures can limit harm from discovered backdoors.
Despite technical advancements, attackers still need to bypass dataset curation and inclusion controls. Yet, the massive scale and openness of data sources remain fundamental challenges for maintaining model security.
Extending Beyond Denial-of-Service
While the current research focused on denial-of-service style backdoors producing gibberish, the same principles apply to more severe backdoors enabling data theft, manipulation, or safety violations. These expanded attack vectors could have serious real-world consequences and intensify the urgency of robust defense development.
Future Directions in AI Security Research
The path forward involves collaborative efforts between AI researchers, cybersecurity professionals, and policymakers. This includes:
Developing scalable defenses and best practices for data poisoning mitigation.
Improving transparency around dataset curation and model training processes.
Building interpretability tools to expose backdoors and aligned misbehavior early.
Creating regulatory frameworks and industry standards guiding safe AI deployment.
Conclusion: Call to Action for the AI Ecosystem
The discovery that a small number of poisoned samples can compromise state-of-the-art LLMs highlights a clear and present danger. As LLMs become integral in critical applications from healthcare to finance to governance ensuring their security and trustworthiness is paramount. Immediate attention, research investment, and proactive defense integration will help safeguard the future of AI.
Research Credit:
This summary and analysis are based on the seminal work by Anthropic and collaborators from the UK AI Security Institute and The Alan Turing Institute. Their comprehensive study titled “A small number of samples can poison LLMs of any size” provides the foundational insights into LLM Data Poisoning vulnerabilities. For full details, visit Anthropic’s research page.
For more expert AI security insights and news, visit ainewstoday.org.



